Local Content Caching: An Investigation
local content caching system for new search engine architecture
Principal Investigators
Overview
Centralized search engines, allowing searching of a fraction of the entire internet, are encountering significant scalability problems as servers struggle to keep up with the exponential growth of content providers and the amount of content provided. A significant problem for a search engine, or any other content "user" for that matter, is keeping an up-to-date (processed) copy of the content of each content provider. Because there is no "protocol" for content providers to let search-engines know that there is new content, or that old content has been deleted or updated, search engines periodically "visit" the content provider, often fetching content that was fetched before. Valuable resources are used in this process, while the results are still inherently out of date.
Another problem is that content providers on the Internet provide content in a form that is good for the human reader, but which is not really ideal for the type of processing needed to create a search engine or similar process.
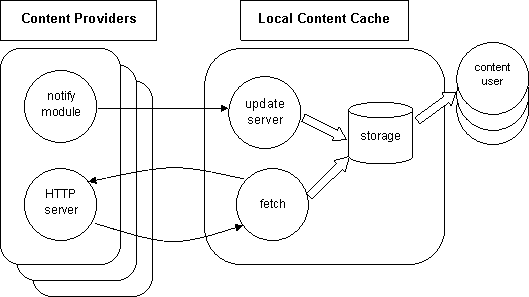
This six month project investigates what is needed to create a local content caching system, in which a content provider can notify a Local Content Cache of new (or updated or deleted) content. This content is then collected by that Local Content Cache, possibly in a form more suitable for content processing than the form in which it is presented to the human reader. Such a Local Content Cache can then be used by a search engine, or any other content "user" such as an intelligent agent, for its own purposes.
It is intended that the Local Content Cache software can be used as a single node in a set of non-overlapping distributed collection points. This is in contrast to the monolithic method of collection used today, where content is directly spidered to a single central location.
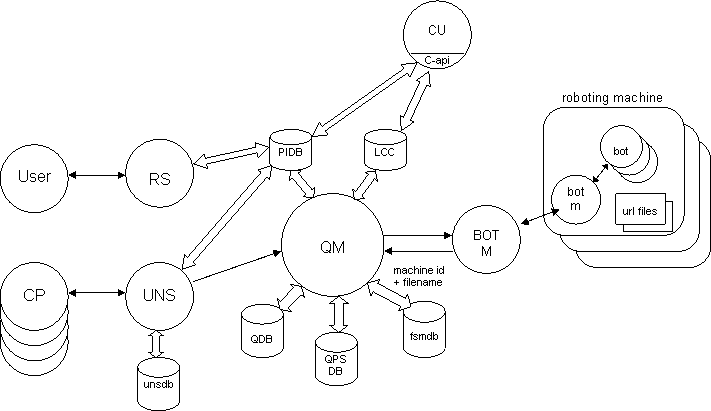
- User Reg
- A person performing the initial registration process.
- RS
- The Registration Server.
- CP
- A Content Provider submitting URL information.
- UNS
- An Update Notification Server. These processes accept sets of URLs from Content Providers.
- UNSDB
- Update Notification Server Database. This is used if the QM is not available.
- PIDB
- The Provider Information Database.
- QM
- The Queue Manager. This process orchestrates URL fetching.
- QDB
- The Queue Database. There is one record per URL to be fetched.
- QPSDB
- The Queue Provider Set Database. This defines an order for URL fetching.
- FSMDB
- Free Space Manager Database. This database is used if various BOT-M processes are not available.
- LCC
- Local Content Cache Database. There is one record per URL in the system.
- BOT-M
- A Robot Multiplexer.
- BOT
- URL fetching Robot.
- CU
- A Content User.