Project Proposal Local Content Caching: An Investigation
local content caching system for new search engine architecture
Principal Investigators
Keywords
Distributed information retrieval, meta-search engines, content caching, content processing, intelligent agents.
Introduction
Centralized search engines, allowing searching of a fraction of the entire internet, are encountering significant scalability problems as servers struggle to keep up with the exponential growth of content providers and the amount of content provided. The main problem for a search engine, or any other content "user" for that matter, is keeping an up-to-date (processed) copy of the content of each content provider. Because there is no "protocol" for content providers to let search-engines know that there is new content, or that old content has been deleted or updated, search engines periodically "visit" the content provider, often fetching content that was fetched before. Valuable resources are used in this process, while the results are still inherently out of date.
Another problem is that content providers on the Internet provide content in a form that is good for the human reader, but which is not really ideal for the type of processing needed to create a search engine or similar process.
This six month pilot-project will investigate what would be needed to create a system of local content caching, in which a content provider can notify a Local Content Cache of new (or updated or deleted) content. This content will then be collected by that Local Content Cache, possibly in a form more suitable for content processing than the form in which it is presented to the human reader. Such a Local Content Cache can then be used by a search engine, or any other content "user" such as an intelligent agent, for its own purposes. A proof of concept implementation of the software needed for a Content Provider, a Local Content Cache and Content Users such as search engines and intelligent agents, will be part of this pilot-project.
In the end, the concept of a "Local Content Cache" can only be successful if there is a sufficiently well defined "localization" of the cache, i.e. which content provider should use which Local Content Cache. In that respect further investigation, and possibly development, will be needed before the Local Content Cache can be really utilized on the Internet as a whole. This further investigation will _not_ be part of this project, but possibly of a follow-up project. However, these issues will be kept in mind when making design decisions in the "Local Content Caching: An Investigation" pilot-project.
The results of the pilot-project will be utilized - in the first instance - by NexTrieve to build a search engine on top of a Local Content Cache, and by any other party that would want to participate in this pilot-project.
Goal
The goal of this pilot-project is to create a functioning proof-of-concept in which:
- one or more Content Providers can notify a Local Content Cache of new, updated or deleted content.
- a Local Content Cache can then fetch the indicated content from the Content Provider in the manner and at the time indicated by the Content Provider.
- the content fetched by the Local Content Cache is stored on the server on which the Local Content Cache software modules are running
- a Content User is able to interrogate the Local Content Cache for a list of new, updated or deleted content.
- a Content User is able to obtain this content from the Local Content Cache.
- a Content User such as NexTrieve (or any other Content User that participates in this pilot-project) can be demonstrated to work on the content as provided by the Local Content Cache.
Furthermore a description of the software, protocol(s) and API(s) developed for this pilot-project will be provided. Recommendations from the team for further (re-)development of these will also be provided. The question as to whether or not it seems worthwhile to continue the pilot-project into a full-fledged project, in which the localization issues are also addressed (which Content Provider uses which Local Content Cache), will also be answered.
All results of this pilot-project are to be made available to the public domain. The copyrighted NexTrieve search engine is excluded from this requirement.
Composition of the Research Team
| Elizabeth Mattijsen | project manager, research & development |
| Kim Hendrikse | research & development |
| Gordon Clare | research & development |
Elizabeth Mattijsen will be responsible for the project management and will regularly report project status. She will also be partly responsible for development work. Elizabeth Mattijsen has over 25 years experience in the development and introduction of Computer Based Training in the workplace. Since 1994 she has been involved with the development of websites on a commercial basis, using the expertise that she gained in CBT. Lately she has been involved in the development of NexTrieve search engine software, particularly the support software written in Perl.
Kim Hendrikse is the original developer and designer of NexTrieve, a project that started back in 1995 with the initial "fuzzy" search engine. He has a broad base of experience in the Unix/C/networking fields gained in New Zealand, London and the Netherlands. In addition to design and development work on NexTrieve, he has developed and maintained two national search engines (one in the Netherlands and one with a virtual presence in New Zealand) and is responsible for the design and maintenance of the company network.
Gordon Clare, a New Zealander by origin, has experience of a wide variety of sofware development fields ranging from real time high resolution image processing though to development of multi-threaded interpreter environments. He has spent several years in France working as a Systems Architect for a distributed C++/C/Java Windows based document management system. Since September 2000 he has been involved with the core development of the new generation NexTrieve search engine working from Rennes, France, with daily internet telephony contact to Echt.
This team has been working on the next generation of the NexTrieve search engine software over the past 1.5 years, recently culminating in the release of NexTrieve 2.0. This team has participated in the Text Retrieval Conference (TREC) in 2001. All team-members have a thorough understanding of the issues involved with the processing of content in different ways.
The infrastructure of Nexial in Echt will be used for this pilot-project. This applies to the technical infra-structure, such as a voice-over-IP connection with Mr. Clare in Rennes (France) allowing for very close cooperation, as well as other (administrative and secretarial) services of the office itself.
Architectural Overview
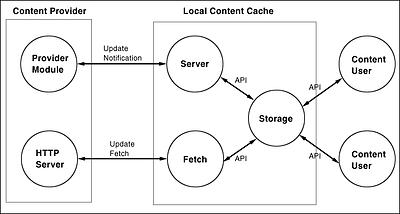
Content Provider
A Content Provider (in the context of this pilot-project) is a server that makes its content available as web-pages using the HTTP protocol. The Content Provider contacts the Local Content Cache whenever it wants the Local Content Cache to fetch specific new or updated content, or when it wants the Local Content Cache to delete content that was fetched before. This process is called "Update Notification". After the Local Content Cache has accepted an Update Notification, it will attempt to fetch the indicated content from the Content Provider: a process we call "Update Fetch".
Content Provider issues that will be addressed in this pilot-project are:
- a configurable (Perl) module for Content Providers, the so-called Content Provider Module.
- the constraints that should apply to the Update Notifications that a Local Content Cache may wish to honour, or "Update Notification Constraints".
- the constraints within which a Local Content Cache may fetch the indicated content from the Content Provider, the so-called "Update Fetch Constraints".
Within the bounds of this pilot-project, a Content Provider Module will be implemented as one or more Perl Modules. It will allow easy configuration for file-system based websites and will also allow database driven websites to supply information for generating Update Notifications.
The Content Provider will also maintain state information about when a specific piece of content was most recently specified in an Update Notification, initially using a very simple database back-end for storage of this state information.
Update Notification
Whenever a Content Provider decides that new content is ready to be fetched by the Local Content Cache, an Update Notification is sent to the Local Content Cache. In this Update Notification, the Content Provider only specifies (among other things) which content should be fetched, not the content itself.
Update Notification issues that will be addressed in this pilot-project are:
- an easy configurable way for file-system based websites to create Update Notifications automatically on a regular basis.
- the type of protocol to be used for the Update Notification: should a new protocol be developed or will it be sufficient to use an existing protocol such as HTTP or FTP?
- checking the authenticity of the Update Notification: how can the Local Content Cache "know" whether the Update Notification is genuine. In the pilot-project only the "known IP-number" authentication will be allowed, allowing Update Notifications only from IP-numbers that are configured to be valid to the Local Content Cache.
- indication of a "fetch" URL and a "virtual" URL, i.e. allowing the Content Provider to provide a special version of the content for the Local Content Cache other than the one normal users would see. For instance, a Content Provider might wish to supply a generic XML version of its content, rather than a completely rendered HTML-version.
- indication of any special authentication that the Local Content Cache should use to do the Update Fetch. The Content Provider may only wish to make an XML version available when secured with a username and password.
- indication of the Update Fetch Constraints.
- indication of other types of data ("attributes") that the Local Content Cache should associate with the content, such as expiration date, copyright information, which Content Users are allowed access, etc.
- the response from the Local Content Cache, indicating either acceptance or (maybe partial) refusal of the Update Notification and the reason why.
- the development of an Update Notification API, which will be used by the Local Content Cache Module for handling the Update Notifications of Content Providers.
Update Notification Constraints
A Local Content Cache may decide to refuse an Update Notification (maybe partly) for a number of reasons. These constraints may be based on:
- type of content: a Local Content Cache may decide not to cache specific types of content, such as (streaming) media files and graphics files. The type of content will most likely be indicated using generally accepted MIME-types, such as text/plain, text/html and application/ms-word.
- overflow of disk-space quota: a Local Content Cache may enforce a maximum amount of disk-space that the content of a specific Content Provider may fill.
- overflow of bandwidth quota: a Local Content Cache may enforce a maximum amount of bandwidth that may be used by a Content Provider in an Update Fetch.
- any other type of constraint that we might find to be useful during the pilot-project.
Update Fetch Constraints
A high powered, high bandwidth Local Content Cache will be capable of "drowning" an underpowered, low bandwidth Content Provider with an Update Fetch. The Content Provider can therefore specify Update Fetch Constraints which will limit the Update Fetch to:
- a specific period in which the Update Fetch should take place, e.g. at night when the load of the Content Provider is low.
- at a specific rate, e.g. no more than 1 file per every 10 seconds.
- at a specific bandwidth, e.g. no more than 64Kbit/second, granularity to be determined.
- any other type of constraint that we might find to be useful during the pilot-project.
Local Content Cache Modules
Within the bounds of this pilot-project, the Local Content Cache Modules will consist of a collection of C-libraries as well as C-programs that:
- can run as a daemon for accepting and handling Update Notification requests from Content Providers, as defined in the "Update Notification API".
- execute the Content Fetch, which, within the bounds of this pilot-project, always consist of an HTTP GET request.
- store the content and its meta-data ("attributes") in the Content Storage, outlined in the "Content Storage API".
- allow Content Users access to the content of a specific Content Provider, as defined in the "Content User API".
Content Storage
The content that is collected by the Local Content Cache from the Content Provider must be stored somewhere. Within this pilot-project a very simple yet modular approach will be taken. Issues that will be addressed with regards to Content Storage and the Content Storage API are:
- an API for storing content fetched from the Content Provider.
- an initial implementation of a content storage backend, probably based on an open-source database system such as MySQL in combination with a ReiserFS-based file storage system. The ReiserFS file system seems particularly adept at handling huge numbers of small files and many files in a single directory, which significantly improves performance.
Content Users
Within the bounds of this pilot-project, only a limited number of Content Users will be allowed to participate. Because the team is familiar with the NexTrieve search engine, this is a logical candidate for an initial Content User in the pilot-project. Another likely candidate is the use of intelligent agents, in cooperation with the SAFIR project.
If the Local Content Cache concept is to be developed further it seems likely that a network protocol will be developed for offering content from a Local Content Cache to a Content User. For the proof-of-concept goal that we want to reach a fully defined network protocol does not seem to be needed at this stage.
Deliverables
The following deliverables will be made available at the conclusion of the pilot-project:
- a configurable Content Provider Module, written in Perl, allowing Content Providers to specify Update Notifications.
- a set of configurable Local Content Cache Modules, written in C, implementing the various API's of the Local Content Cache.
- the pilot-project Final Report, in which the findings of various implementation issues and decisions will be described. Recommendations for the future development of the Local Content Cache concept will also be made.
It seems appropriate to dedicate a separate server for the development and testing of this pilot-project. One way of obtaining the use of a server for the duration of the pilot-project is to lease one (including bandwidth) at XS4ALL. An alternative could be that an investment is made in a machine: this would be more costly initially, but such a server would also be available without additional cost in a possible follow-up project. Any other way in which a separate server with enough bandwidth can be made available for development would also be fine, including use of servers supplied by Nexial Systems.
Phases
The project will be divided up into 4 phases, each with their own deliverables. The first two phases will be 4 weeks each, the last two phases will be 8 weeks each. The amount of work in each phase will approximately be the same, but more overhead will be involved in the last two phases as they are spread out much more in time.
The following deliverables will be available for review at the end of the respective phase:
- Phase 1: exploratory phase
- In this phase a detailed Project Design will be produced. This will entail an initial specification of the Content Notification protocol along with definition of the components that comprise the system as a whole and their interfacing requirements. Any minimal testing that is necessary to verify the validity of the design will also be done during this phase. To ensure that any source developed for this project will be open source, the project will use a service such as SourceForge as a project repository and create a mailinglist for the discussion of the project.
- Phase 2: initial development phase
- In this phase most of the development of the Content Provider Module as well as most of the Local Content Cache modules will be done. At the end of this phase a fully operational, CPAN ready, Content Provider Module will be provided with basic documentation, as well as Local Content Cache modules in C that are capable of doing a Content Notification -> Content Fetch cycle and storing the result in the Local Content Cache.
- Phase 3: refinement of protocols and modules
- The third phase will be used to further refine the protocols and modules developed and transform the software into a form suitable for external use. During this phase, the world will be made aware of this project in a wider manner, inviting people to participate in this project as a content provider. At the end of this phase complete and ready-to-use fully documented modules will be available using as much of the feedback from the world as possible.
- Phase 4: content users and final project report
- In this phase the activities start to shift from a purely developmental and research type to a more "gospel spreading" type of activity. This phase will also be used to accommodate the content users of the Local Content Cache, by supplying them with an initlal API for obtaining information from the Local Content Cache. Content users of the Local Content Cache will at least be one GPL search engine, such as ht://Dig or SWISH++, and the NexTrieve search engine software. The final report with recommendations for the future will also be made available at the end of this phase.