
The AGFL-GNU project proposal
parser generator system for natural languages
1 Proposer
Prof. C.H.A. Koster
Dept. Computer Science
University of Nijmegen
6525 ED NIJMEGEN
The Netherlands
kees@cs.kun.nl
http://www.cs.kun.nl/~kees
2 Goal of the project
The goal of this project is to make the AGFL linguistic parser generator system publicly available as a tool for the development of NLP-based applications.
Natural language processing (NLP) is an important enabling technology for future web-based applications: from filtering and narrowcasting to more intelligent search machines and services based on the automatic interpretation of the contents of documents. The state-of-the-art in search machines on the web is based mainly on the use of keywords, applying linguistic techniques to enhance recall. An example is the Linguistix software library, incorporated in commercial search machines like Altavista and Askjeeves, which performs tagging, lemmatization and fuzzy semantic matching.
Besides individual keywords, some use is made of phrases, but this is mostly limited to those noun phrases which can easily be extracted. An important step forward in precision is to be expected from the use of more complicated linguistic phrases, including the verb phrase. Progress in this respect is hampered by the lack of parsers for natural languages, which can extract and normalize all phrases suitable for Information Retrieval applications, with sufficient speed and precision.
Present day natural language parsing technologies are still of limited value to applications:
- most sophisticated parsers have been developed for mechanical translation rather than for retrieval purposes
- most parsers are developed using proprietary software, few are in the public domain, so there is little synergy between projects
- parsing speeds are generally low in relation to the speed of the Internet.
That is why there is a need for tools, available in the public domain, and suitable for the development of efficient parsers for Information Retrieval applications. The AGFL system is such a tool.
3 About AGFL
The AGFL system is a system for the development of grammars for natural languages and the automatic generation of efficient parsers from such grammars. The AGFL formalism (Affix Grammars over a Finite Lattice) is a notation for Context-Free grammars with finite set-valued features, acceptable to linguists of many different schools.
The research group on Compiler Construction at the department of Computer Science of the University of Nijmegen has been collaborating over a long period with the Department of Language and Speech at the same university, supplying syntactic technology (formalisms, parser generators and tools). Based on the experiences obtained in research and teaching with the EAG (Extended Affix Grammar) formalism, in 1991 a simple form of Unification Grammars especially suited for the syntactic description of natural languages was defined: AGFL. This formalism was implemented with subsidy from the Dutch national research organization NWO (SION and ST) in the form of a parser generator with an efficient lexicon builder.
Over the last decade, AGFL and the AGFL system have been used for research and development purposes by a number of groups in linguistics and Information Retrieval research:
- The department of Language and Speech of KUN has developed grammars in the AGFL formalism for English (TOSCA, J. Aarts and N. Oostdijk) and Dutch (AMAZON, J. van Bakel and P.-A. Coppen).
- On the basis of TOSCA, the ICE grammar of spoken English has been developed and used to construct the ICE treebank, in collaboration with London University.
- The Dutch grammar Amazon has been further developed in the Esprit project DORO (Document Routing) by J.Potjer and S. van Dreumel and has been integrated into the the LCS system for the automatic classification of human-readable documents. This system has been applied in the routing of mail for an Insurance company.
- In the same Esprit project large grammars for Spanish and Modern Greek have been developed by groups at the University of Santiago (P. Santalla) and the CTI in Patras (D. Noussia).
- In the European project CRYSTAL, G. Tabuteau from CAP-Gemini has implemented an Information Retrieval grammar for French.
- In the Condorcet Project at the University of Twente (K. Mars) a grammar of english has been developed by B. van Bakel and E. Oltmans for the automatic extraction of index terms from technical texts.
- A grammar of Modern Standard Arabic is being developed by E. Ditters, which is used in the European corpus project DIINAR (with the University of Lyon and a number of Arabic universities).
- A grammar of Russian is being developed by I. Azarova at the University of Sankt Peterburg.
- Work has started by M. Bilinsky at the university of Lviv on a grammar of Ukrainian.
The AGFL system is presently available on UNIX and Windows systems. The website http://www.cs.kun.nl/agfl/ offers some example grammars, demo's, free software and documentation of the system and the formalism.
Developing a grammar is a very time consuming process of continuous improvement, but far preferable to writing a parser by hand. The AGFL system serves to generate automatically a parser from a grammar and a lexicon.
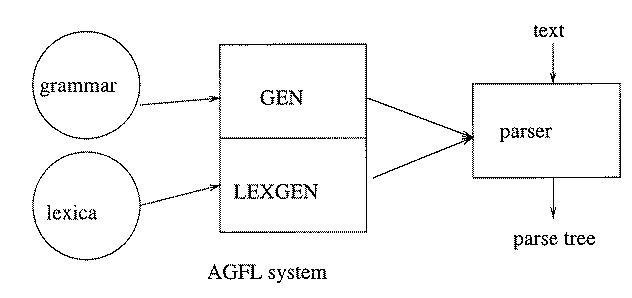
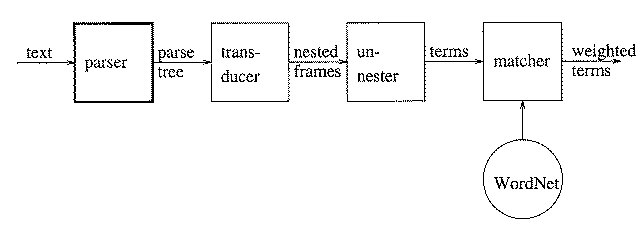
The resulting parser is used e.g. in the DORO system developed in Nijmegen as the first step in extracting phrases from a document and turning them into indexing terms.
In generating parsers from an AGFL grammar, the system applies a battery of optimizations that greatly increase their speed. With an average parsing speed of 1000 words (5000 bytes) per second on a PC the English parser in the Condorcet project can reasonably match the speed of the Internet.
4 AGFL and GNU
The goal of the present project is to bring the AGFL linguistic parser generator system into the GNU family, so that a wider audience of linguists can use it to develop grammars, which can then be used in different Information Retrieval projects and in the development of commercial products.
There is at present no parser generator for linguistic grammars under GPL. AGFL can fill a niche that will make GNU attractive to a large number of linguistic users who now live in a Microsoft-dominated world. AGFL is a well-developed and stable system, which merits professionalization and availability in the public domain. A university like ours is not in a position to distribute and maintain the system on a commercial basis. The GPL conventions provide a rational framework for its distribution and use. The open availability of the source text will invite contributions by others in improving the software and will ease the maintenance problem. Finally, the AGFL system would be one of the few European contributions to the GNU effort.
It is our expectation that the availability of a reliable and efficient parser generator for natural language parsers in the public domain will not only enable many new projects, but that the good example of making this software system freely available will inspire others to produce grammars in the public domain.
5 The work plan
The total amount of work is estimated at 20 man-months, with a beta version available after one year. A computer scientist suitable for this task and interested in the project (Erik Verbruggen) will shortly be available. The project will be managed by the proposer, who will also supervise the changes in the formalism and present the project to the outside world.
A student assistant will be employed for 12 months @ 40 Hrs (3 MM) to improve the user interfaces and to create interactive debugging aids.
5.1 Tasks
The tasks to be performed, with an estimation of their size in ManMonths (MM), are as follows:
- T1 improving the GEN and LEXGEN components of the AGFL system
- making both the system and the parsers generated from it more attractive, more general, more useful and more efficient
- T1.1 revising the AGFL formalism (2 MM)
- unifying and simplifying the notation, revising the type system, implementing the modifications
- T1.2 generalizing the formalism (2 MM)
- implementing mechanisms for probabilistic parsing, trellis input and output
- TI.3 improving the implementation and API (2 MM)
- making the system configurable according to the GNU standards, providing for other type fonts in grammars and lexica (cyrillic, arabic etc), correcting known bugs, improving annoying details
- T1.4 improving performance of generated parsers (2 MM)
- implementing follower-set optimization, left-factorisation.
- T1.5 improving the user interface (3 MM student assistant)
- implementing an interactive shell (Grammar Work Bench) around the system to make it more interactive and easier to use by different categories of users (linguists, IR specialists etc.); implement interactive debugging aids for parsers (tracing and profiling).
- T1.6 preparation for distribution (1 MM)
- bringing the system in distributable form, severely testing the final system.
- T2 professionalizing the documentation
- Apart from documentation to accompany the software, the proposer intends to write a textbook describing the properties and use of the formalism.
- T2.1 better system documentation (3 MM)
- T2.2 better user documentation (1 MM)
- T2.3 adding a suite of examples (1 MM)
- T2.4 example application relevant to the WEB (2 MM)
- defining and implementing a simple, convincing and easily extendable application on the WEB, including a core grammar of English with an extensive lexicon.
- T3 dissemination
- introducing the system to the GNU family and to potential users.
- T3.1 bringing AGFL under GPL (1 MM)
- convincing the GNU guardians, satisfying the boundary conditions imposed by the GPL license, transferring the software for distribution.
- T3.2 involving the users (2 MM)
- collecting bug reports, analysing them and responding; response to user questions and user wishes; maintenance of WEB page.
- T3.3 creating awareness (1 MM)
- presentation at USENIX workshop and/or NLUUG conferences; holding an AGFL workshop for linguists and starting a user group.
5.2 Time schedule
Since the relative order in which the tasks are performed can not be precisely predicted at this point, we indicate the tasks to be completed in each six-month period and the expected deliverables.
| period | Tasks completed | Deliverables |
|---|---|---|
| first half year | T1.l, T1.2, T2.2, T2.3 | alpha version for selected users |
| second half year | T1.3, T1.4, T3.2, T1.5 | beta version of the complete AGFL system |
| third half year | T3.1, T2.1, TI.6, T3.3 | final version of the AGFL system |
| last two months | T2.4 | example application relevant to the WEB. |