To solve many of the World Wide Web's scalability problems, we claim that it is necessary to change the existing Web architecture. Solutions to some scalability problems exist, but they do not address the fundamental client-server nature of HTTP. Our proposal is to move beyond HTTP - to replace it with a new and scalable architecture. To this end, we present a Web model based on Globe distributed shared objects. Web resources, in this model, are encapsulated in Globe distributed shared objects. Each such object, depending on its needs, can determine its own distribution strategy. We claim that the flexibility of this approach is what allows a Globe-based system to scale. This paper presents the design and technical details of the Globe-based Web model and its implementation. It describes the object model and system services needed to support the objects. GlobeDoc, an example of an encapsulated Web resource, is also presented.
HTTP replacement, scalability, distributed objects, Globe, design, implementation
There are currently numerous problems plaguing the Web, the symptoms of which are well known to even the most casual users - slow connections, sites that occasionally become unreachable, inconsistent documents, broken links, etc. These are primarily due to the growing size of the Web (in terms of users, number of available resources and resource size) combined with nonscalability of the Web infrastructure, the lack of location transparency in Web resource naming, and the many attempts to fix the problems. The Web infrastructure is based on HTTP, a simple client-server protocol. Overloading of the Web occurs because Web resources are usually hosted on single servers. When the demand for a resource becomes high the servers (or their network connections) eventually cannot handle the load and a slow, or in more extreme cases no, response is the result.
Solutions to these problems rely on traditional scaling techniques such as caching and replication and include proxy caching, mirroring, and clustering. Due to the client-server nature of the Web, these solutions generally consist of mechanisms outside of HTTP and do not address the fundamental client-server nature of it. Often, they only partially solve the problems. For example, clustering solves the problem of overloaded servers, but not that of saturated network connections. At the same time they introduce new problems such as inconsistent documents What's more, these solutions are often ad-hoc, leading to a myriad of different, incompatible and often unmanageable solutions. There is, for example, no standard way of creating consistent Web site mirrors, and Web site administrators often have to create their own solutions. This quickly leads to a situation where many different incompatible and suboptimal mirroring solutions are being used. Many proposed solutions are also too restrictive - they generally take a one-size-fits-all approach, applying the same solution to every resource. For example, most caching solutions have one caching algorithm that is applied to every cached Web resource. We claim that in order for the Web to scale, it will be necessary to apply distribution solutions to individual Web resources depending on their needs and characteristics [13].
In addition, the naming scheme used in the Web aggravates many of the scalability problems because it is not location transparent. Each URL contains a Web server address, which means that when resolving the URL and retrieving the resource, only the referenced server can be contacted. Solutions utilizing clustering or mirroring of Web sites have to deal with this problem and often come up with schemes that require use of dynamic DNS tables, or even modifying IP routing tables to allow the address in the URL to refer to more than one actual server [8]. This problem with naming in the Web has been widely recognized by the Web community and work is currently being done on a new location-transparent naming structure (URNs)[24].
Limited flexibility with regard to the introduction of new resources and services is another problem of the current Web infrastructure. Although nonstandard resources, such as Java applets, have been integrated into the Web, the means by which this is done usually requires a unique solution for each new type of resource. Creating such solutions is not always an easy task, and the results are rarely elegant.
Given these problems, we claim that it is necessary to replace (or at least radically change) the existing foundation, and thus move beyond HTTP. A replacement must have the following characteristics. It must be scalable, that is, it should offer an infrastructure that will be able to handle a growing number of users, resources, and requests per resource worldwide. Resource names and references must be location transparent, and remain valid if the resource is moved or distributed over multiple locations. It must be flexible and extendible, so that new resources and new solutions can easily be added (without having to resort to solutions outside the system), and last, but not least, the solution should not degrade overall system performance.
We propose to use Globe as a foundation upon which to build beyond HTTP. Globe is a wide-area distributed system based on the concept of distributed objects that fully encapsulate their own distribution policies (i.e., replication, migration, partitioning, etc.) A detailed description of the Globe model can be found in [26]. We believe that Globe has the necessary characteristics to provide a good replacement for the current Web infrastructure. By providing a framework that lets scaling techniques be applied on a per-object basis Globe allows scalable components and applications to be created. Also, because Globe allows distribution strategies to be tailored per object it is possible to apply optimum strategies per object based on the object's (expected) usage and characteristics (for more information, see [21]).
Flexibility and extendibility are provided by Globe's interface-based object design and modular object structure. An interface-based design means that Globe object clients call methods through interfaces that are independent of actual method implementations. Method implementations can, therefore, change (or be replaced) without modification of clients that use them.
Internally, Globe objects are built up modularly out of subobjects. This means that specific object parts can be replaced without affecting any of the other parts. It is therefore possible for an object's distribution strategy, for example, to be replaced without having to go through the trouble of reimplementing the whole object.
Globe also has scalable naming services that provide location transparency. In Globe, object names are separate from, and are independent of, their location - an object may change its location yet keep the same name, or an object may have many different names all referring to the same location. This transparency is achieved by splitting naming and locating objects into the two separate services. A name service is used to resolve symbolic, user-defined names to object handles. An object handle is a fully location-independent and globally unique, persistent, object identifier. Object handles are, in turn, resolved by a location service to object contact addresses. A contact address describes where and how an object can be contacted. The name and location services will be described in more detail later.
The goal of this paper is to describe a Globe-based replacement for the current Web architecture. This paper will focus more on the design and technical details of the Globe Web architecture than on motivation for our (design) choices, as these have already been covered in other papers [refs]. Contributions made by this paper include an insight into how an alternative Web platform can be organized and built that solves many of the current problems. We also present details about our experience with this platform. Recognizing that changing the Web is a continuously evolving process, we show how such an alternative platform can be fully integrated into the current Web.
The rest of the paper is structured as follows: the next section will present the model for our Globe Web architecture, followed by a section describing all the system components in detail. After that, the next two sections will present an example of how Web documents are implemented as GlobeDoc objects in this Globe based Web architecture, and a discussion of how other Web resources could be implemented as Globe objects. Practical experience with a GlobeDoc test setup is then presented, followed by a section on related work and one presenting conclusions and future work.
In the Globe Web model Web resources, that is, all things that can be accessed on the Web (e.g., Web pages, sound files, streaming audio, etc.), are encapsulated in distributed objects. Each Web resource is encapsulated in an appropriate class of object. For example, corresponding to the various kinds of Web resources mentioned above, there could be a class for Web pages, a class for sound files, one for streaming audio, etc. Each object offers one or more interfaces, with each interface consisting of one or more methods.
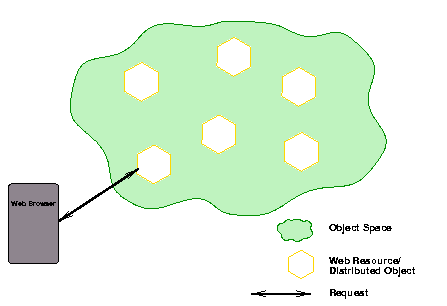
By encapsulating these resources in distributed objects, the Web is transformed from a collection of clients and servers serving Web pages into an object space of distributed objects (see Figure 2.1). To access Web resources, clients must look up the objects that they are interested in and connect to them. Once connected, the clients call appropriate methods to retrieve the object contents and present them to their users.
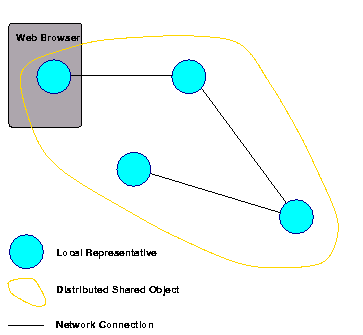
Distributed objects in Globe are physically distributed, meaning that they are literally spread out over multiple address spaces; we call them distributed shared objects (DSOs) as an analogy to distributed shared memory. Each DSO consists of a number of local objects, called local representatives (LRs), one in each address space covered by the object (see Figure 2.2). Local objects are objects that are completely contained in one address space and can be implemented in any supported (not necessarily object-oriented or object-based) language.
The benefit of DSOs is that the complete DSO state may be copied or partitioned over any of the local representatives. In some distributed shared objects, the LRs may contain replicas of the state, in others the full state may be contained in only one of the LRs, and in still others each LR might contain only a part of the whole state. Globe DSOs allow this distribution of state to be determined by the object implementation itself. Because the state distribution is encapsulated within the object, Web resources may be transparently replicated or partitioned - that is, neither clients, nor other objects or system components need to be aware of an object's distribution policy. An object's distribution policy can be set to one that suits the object's needs (i.e, the way that it is used), and need not depend on some global system policy.
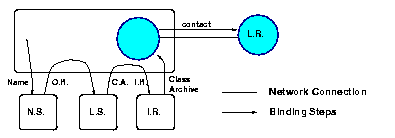
To communicate with a Globe DSO, clients must bind to the object. Binding causes a new LR to be created in the client's address space, effectively connecting that address space to the rest of the DSO. The binding process has two main phases: finding the object, and installing and initializing the LR. Before giving all the details of the binding process in the next section, we first present a brief overview.
In the first phase, a binding client starts by passing a name of the DSO to the name service (referred to as "NS" in Figure 2.3). The Globe name service is responsible for mapping names to globally unique, location-transparent object handles (OH). The name service returns an object handle, which is then passed on to the location service (LS). The location service maintains a mapping of each object handle to a set of contact addresses (CA). A contact address represents a contact point of the DSO, analogously to service access points in computer networks. One or more of these addresses are returned to the binding client. For simplicity, we assume only one address is returned.
A contact address identifies an implementation of a LR that should be loaded into the client's address space. The second phase therefore starts with passing an implementation handle (IH) identifying that implementation to a local implementation repository. The implementation handle is part of the contact address. The implementation repository, in turn, returns the implementation in the form of a class archive. A class loader subsequently extracts the implementation code from the class archive, loads it into memory, creates the actual LR and initializes the LR. Once the LR is initialized, the client will be able to communicate with other parts of the DSO. We say that client is now bound to the DSO. The LR in the client's address space is said to be connected to the rest of the DSO.
Splitting the binding process into these different steps, makes the whole system more flexible. As mentioned before, naming and location are separate services so that object names and object locations can be kept separate. The implementation repository is kept separate form the location service for a similar reason. For example, it is conceivable that contact addresses could be stored and reused by clients to avoid having to resolve names and object handles. By separating naming from location, we avoid that names need to change when an object changes its location, or when it is replicated. Our contact addresses are comparable to the (location-dependent) object references in Java RMI. However, in Java RMI, an object reference is actually a complete serializable proxy that is handed out between different processes. By separating implementations from contact addresses, it becomes possible to return client-specific implementations. For example, a client may prefer to use only implementations that have been certified.
Implementing the Web as a collection of Globe DSOs requires structural support for the DSOs. This includes providing address spaces for local representatives, access to the services used during binding (i.e., name service, location service, etc.), and a means to access objects from client Web browsers. Figure 2.4 shows the elements of an infrastructure that we have implemented, and which provides this necessary support for implementing the Web in Globe. A detailed description of each the components is given in the next section.
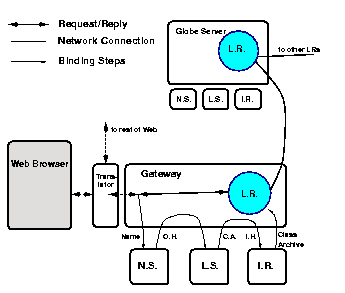
In our approach, a browser sends requests to a proxy, called the translator, which filters Globe-specific names from regular URLs. Names of Globe DSOs are subsequently forwarded to a Globe gateway. The gateway binds to the referred object and calls the appropriate methods when binding has completed. Nonclient LRs of a DSO are contained in Globe servers, which each provide an address space and runtime services to LRs. Apart from also processing client requests, much of the functionality of a gateway and Globe server is the same. If desired, it is possible to include much of the translator and gateway functionality in the browser itself. More details on such Globe-aware browsers is presented later.
We now describe each of the components shown in Figure 2.4 in more detail.
The name service implements a name space for Globe distributed objects by mapping Globe object names onto object handles. An object handle is resolved to an address where the object can be contacted. Object handles and contact addresses are intended to be used for automated processing only. In contrast, a Globe object name is a user-defined and human-readable character string. There is an N-to-1 relationship between object names and object handles: different names can refer to the same object handle, but each name refers to exactly one object handle.
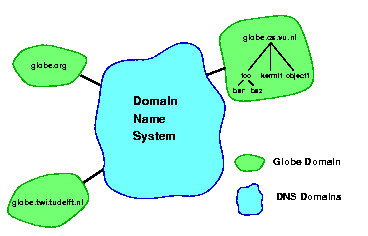
The organization of the Globe name space is very similar to that used in, for example, UNIX file systems. The name space is organized as a hierarchical rooted tree, in which an interior node represents a directory, and a leaf node represents a Globe object. An edge is labeled with the (simple) name of the node it points to. A composite object name is a sequence of labels representing a path in the name space. As in UNIX, the labels are separated by a slash ("/"). An absolute object name, that is, one that represents a path starting at the root of the name space, has a slash as its first character. Composite object names in Globe are always absolute. Object names are resolved in the usual (iterative or recursive) way, and eventually result in the object handle of the object to which the name refers. Globe object names in the Web follow the URI syntax, by preceding them with the "globe" scheme identifier. For example, the Globe name /nl/vu/cs/globe/foo becomes globe://nl/vu/cs/globe/foo.
The current name space implementation is largely based on DNS [16] name servers. In this implementation the assumption is made that the root as well as (hierarchically) higher-level nodes in the name space correspond to regular DNS domains. In theory, leaf nodes, which represent actual DSOs, and lower-level interior nodes also correspond to domains, but these are implemented in a Globe-specific way. A Globe domain, that is, a domain that is not a regular DNS domain, is implemented by a Globe domain server. This server consists of two parts. The main part is formed by a name server that implements the subtree rooted at the node represented by the Globe domain. This subtree corresponds to a DNS zone. For this implementation we use BIND8 [2] to implement the name servers. The second part consists of what we call a naming authority, which is a server colocated on the same machine as the name server, and which is the only server allowed to invoke update operations at the name server.
To adhere to DNS naming syntax, we transform a name such as globe://nl/vu/cs/globe/foo into foo.globe.cs.vu.nl. The DSO name (e.g., foo.globe.cs.vu.nl) is passed to a DNS resolver as though it were a regular host name. The resolution eventually always reaches a Globe name server (e.g., the server for globe.cs.vu.nl), which resolves the remainder of the name to the appropriate object handle.
Details on the name service implementation can be found in [5].
An object handle is resolved to one or more contact addresses by the location service. As mentioned, an object handle is a location-independent and universally unique object identifier. Because it is globally unique, it can be used as a worldwide object reference. A contact address describes a contact point, which is an address where a DSO can be contacted. It contains information about where and how the object can be reached. This is contained in an implementation handle that identifies an implementation of the LR needed to contact the object. Besides the implementation handle, a contact address also contains data used to initialize the LR, and includes the actual network address of the contact point. Whereas a DSO has only one object handle that does not change throughout its life, contact addresses can be added, removed or updated as necessary.
Because the location service stores all the contact addresses, it must be capable of storing and supporting frequent updates of large numbers of contact addresses. It must also be able to efficiently resolve object handles to contact addresses. To ensure scalability, it is essential that the location service exploits locality.
We have designed and implemented a location service, of which the details can be found in [25]. The service is implemented as a worldwide distributed search tree, in which all requests for updates and look-ups are initiated at leaf nodes. If a leaf node cannot handle a request, the request is forwarded to its parent. In this way, we exploit locality and achieve scalability. To avoid that higher-level nodes are swamped with requests, we partition these nodes by dividing the set of object handles using a hashing technique. It is beyond the scope of this paper to explain in detail the implementation of the location service.
The implementation repository is a service that stores LR implementations and makes them available to binding processes. LR implementations are stored and transferred as class archives, which are archive files that contain all the implementation code needed by a LR. Storing the entire implementation of a LR in a single class archive, makes its transportation and management easier compared to having multiple files. In our Globe implementation, a class archive is a Java jar file and contains the many Java class files that form the implementation of a LR.
When a LR implementation is registered at the implementation repository it is assigned an implementation handle. An implementation handle is placed in a contact address and subsequently used by a binding process to retrieve (copies of) the implementation. An implementation handle is an opaque identifier that is generated by an implementation repository. Currently, we support only file URLs as implementation handles, that is, a handle simply contains the path name of a locally available class archive file. Other schemes, such as those based on ftp or http URLs, may be preferred for a wide-area system such as the Web. We plan to support such URLs as well.
Better than URLs, however, are logical names such as URNs, which are globally unique and location transparent. Location transparency gives us the benefit that we can easily set up a distributed implementation repository, but without the drawbacks of having to make its distribution visible to the users. For example, it becomes easier to move or replicate files without affecting their name as known to users.
Besides location transparency, URNs also have the benefit that they do not have to refer to specific class archives. In other words, we can use a URN as a specification for an implementation type. When an implementation handle specifies a LR type, the implementation repository is given the freedom to choose an appropriate class archive for the requesting client. A class archive in this sense thus acts as an instance of the implementation type of the LR. The choice for a specific class archive could, for example, be influenced by the particular platform of a client, or by security requirements. In this way, clients binding to Globe objects can keep control over the code loaded into their address spaces.
The gateway and Globe server both provide address spaces and runtime services to LRs. The difference between them is that the gateway's main goal is to provide clients with access to LRs and their methods, while the Globe server provides an environment for nonclient LRs. The gateway is usually placed either very close to a client (e.g., on the same machine or the same local network) or is actually part of the client process. It provides facilities that allow clients to bind to DSOs and call methods on the resulting LRs.
When the gateway is a separate process, it must provide an external interface through which clients can bind to a DSO and call its methods. This can take the form of a dedicated RPC-style interface, or a server that accepts custom HTTP requests from clients. When the gateway is integrated in the client, the client can perform method calls directly on the LRs as both will be in the same address space. The client will also have direct access to the Globe runtime system and can use its services and resources to bind to DSOs.
A Globe server always runs as a separate process. It has a remote-accessible interface that allows LRs, other Globe servers, or administrators to request services from it. These services include binding to a DSO, unbinding from a DSO, as well as creating or destroying a DSO. A binding request causes the Globe server to bind to a given DSO, resulting in a LR of that DSO being created in the Globe server. Likewise, a Globe server can be requested to unbind from a DSO, eventually leading to the LR of that DSO being removed from the server's address space.
In the remainder of this section, we concentrate on the Globe server only. The Globe gateway has very similar semantics, except that it can support only client LRs. In practice, this means that a Globe gateway cannot offer a contact point for a DSO. The most important function of a Globe server, is that it provides access to services such as the naming and location service, facilities for binding to a DSO, and local services to LRs contained in its address space. These issues are described next.
The naming service, location service and the implementation repository are all external services, that is, they are implemented outside of the Globe server. Because LRs (and other runtime system components) can access only resources in the Globe server's address space, the runtime system provides local proxies to the external services. These proxies, called resolvers, provide local interfaces through which the external services can be used. They can be implemented as simple proxies that forward all requests and replies to and from the actual services, or they can be more complex, storing and manipulating their own local state (e.g., to cache results). The latter are often used to improve system performance. Performance of access to external service is important because it can greatly affect the overall performance of the client-to-object binding process.
The Globe server also provides the facilities needed for binding. These are encapsulated in a binding object, which is a local object that makes up part of the runtime system. Binding in Globe consists of at least three steps: (1) name resolution, (2) object handle resolution, and (3) loading and initialization of a LR. Normally, binding starts at the first step. It is, however, possible to begin binding at any other step, as long as the information needed by that step is present. For example, to start binding at the second step, a client would need to have an object handle to pass to the location service. The binding object provides separate methods for each step of the binding process. Each of these methods can store their intermediate results for (possible) later use. For example, a Globe server might store an object handle as previously returned in step 1, to avoid a name look-up at the name service when it is requested to bind to that same object again later.
When a Globe server is requested to unbind from a DSO, effectively, its LR for that DSO has to be disconnected from the rest of that DSO. Disconnecting a LR from the rest of a DSO is generally object specific. For example, it may be necessary to migrate the LRs state to another Globe server. In other cases, it may be safe to simply discard the state because the LR is, in fact, a replica. Also, if the Globe server was offering a contact address for that DSO, this address will have to be removed from the location service. Therefore, when unbinding from a DSO, we assume that the DSO implements its own disconnection algorithm. When the LR has been disconnected, the server then simply reclaims local resources and removes the LR from its address space.
However, it is not always wise to immediately fulfill a request to unbind from a DSO. Consider, for example, a Globe gateway that has just bound to a DSO to return information that is to be displayed in a client's Web browser. In the same style as HTTP, the gateway could decide to immediately unbind from the DSO as soon as it has passed the information to the browser. However, it may be much more efficient to stay bound to the DSO, anticipating more requests for that object. In effect, a server or gateway can decide to cache a binding for later use. In our current implementation, which supports only passive Web documents, the effects of caching bindings turns out to be comparable to that of traditional Web caches.
A Globe server also needs to take care of local resources. Providing an address space for LRs is straightforward. LRs are passive objects, which means that they do not have an active thread of execution. Therefore, the Globe server needs to provide memory to load the LR code. To assist in having multiple LRs in its address space, memory management is handled by a local garbage collector that is responsible for cleaning up memory after LRs when they are no longer referenced. In addition, it should provide the runtime support needed by the implementation of a LR. For example, A Java virtual machine and accompanying runtime library are needed to support Java implementations of a LR.
Although LRs are not active objects, they do require thread management facilities. For example, a thread is started when a message comes in from another LR. These thread facilities are provided by the runtime system. The runtime system also offers access to low-level resources such as communication points (e.g., sockets) and persistent storage (such as files on disk). These resources are all offered through standard interfaces that are platform independent.
As mentioned earlier, a local representative is a local object that is wholly contained in one address space. A local representative implements the interfaces exported by its DSO. Each LR may implement these interfaces in a different way, depending on its role in the distribution strategy of the DSO.
For example, in a DSO with only one copy of the state, there will be a "primary" LR that contains that state. Other LRs in that DSO will implement the DSO's interfaces by simply forwarding requests to the primary. However, when the state has been replicated across multiple machines, a LR may hold a local copy of that state. In that case, when a client invokes a method, that method may have to be propagated to all other LRs, as in active replication [23].
The aim in Globe is to support object developers by separating functionality from distribution. In principle, an object developer should be able to concentrate only on designing and implementing the object's basic functionality as specified in that object's interfaces. Separate from this activity, a developer should concentrate on how that functionality is to be distributed and replicated across a network. We refer to the latter as designing and implementing a distribution strategy. It is this separation of concerns that gives Globe much of its flexibility.
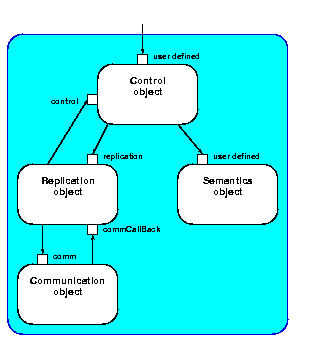
Separation is achieved by constructing LRs in a modular way. A LR is built up of (at least) four subobjects, each responsible for a different part of the functionality, as shown in Figure 3.2. The communication and replication subobjects work together to implement the distribution strategy of a DSO. The replication subobject takes care of replication and consistency issues, while the communication object is responsible for exchanging messages with other LRs. The semantics subobject implements the actual functionality of the DSO. A DSO's state is generally stored in the semantics subobject of its LRs. Finally, the control subobject takes care of invocations from client processes and controls interaction between the semantics and replication subobject.
We return to precise definitions of interfaces below, when we discuss the implementation of Web pages in terms of Globe.
Ideally, users should be able to use their regular Web browsers to access Globe encapsulated Web resources. Unfortunately, current browsers are incapable of resolving Globe URIs as they do not understand globe: schemes. A way around this problem is to use Globe-aware proxies. These are Web proxies [14] that filter out Globe requests and send them to a (local) Globe gateway. The gateway binds to the appropriate objects and performs methods on it on behalf of the user. Any results from the methods are returned to the user's browser through the proxy. Non-Globe requests are passed to appropriate servers, as in regular proxies.
A disadvantage of the proxy approach is that all requests from the browser (including non-Globe requests) must be forwarded through the proxy. As a result, the proxy must be able to handle all the various kinds of schemes supported in URLs, or forward them to a proxy that can. An approach that avoids this problem uses a Globe translator. This component translates Globe URIs to what we call embedded URIs. An embedded URI is a regular HTTP URL that contains an object name and a gateway address, such as http://globe.cs.vu.nl/nl/vu/cs/globe/object. When an embedded URI link is clicked, an HTTP request for the embedded object name is sent to the gateway. The gateway binds to the object and calls methods on it as usual, except that results are passed to the translator. At the translator, each link consisting of a Globe URI, is rewritten to contain an equivalent embedded URI. The modified result is then passed on to the browser. In this way, access to non-Globe Web resources is not affected by the added ability to access Globe resources.
We have recently been experimenting with Globe-aware Web browsers. These are browsers that can natively resolve Globe URIs and bind to the corresponding Globe objects. They basically have the gateway functionality built in. Rather than build a Globe-aware browser from scratch, we are investigating the use of browser plug-ins to add Globe functionality to existing browsers. Such plug-ins are loaded and used when URIs with appropriate scheme identifiers are accessed. We have currently modified Mozilla (the open-source version of Netscape's browser) to support protocol plug-ins. Microsoft's Internet Explorer already supports this extensibility, while Mozilla is officially adding it as well. This approach is ideal as it allow seamless integration of Globe-based Web resources to be realized with very little inconvenience to the users.
To demonstrate how the Web can be improved we introduce a Globe DSO implementation called GlobeDoc. A GlobeDoc encapsulates an entire Web document, that is, a collection of logically related Web pages including additional elements such as icons, images, sounds, etc. We consider only simple Web pages that do not contain, for example, elements that interact with a server, such as forms. Elements in a GlobeDoc may contain internal as well as external hyperlinks. An internal link refers to an element in the same GlobeDoc, whereas an external link refers to an element in another GlobeDoc. Every GlobeDoc assigns one element to be the root. The root provides access to other elements through internal links, and is somewhat comparable to the index.html file. Because we do not say anything about the contents of an element, every element has a set of properties associated with it. At the least, these properties include a MIME type that describes an element's contents.
Web documents are the first type of resource that we have encapsulated in a Globe object. The reason for choosing Web documents is that they provide a good granularity for Globe objects: all their elements are related and usually accessed at approximately the same time and from the same client. This means that all the elements will have approximately the same access pattern, and would benefit from a similar distribution strategy. GlobeDocs are also simple to implement, yet cover a broad enough group of existing Web pages that interesting experiments can be performed with them.
As described above, the GlobeDoc model is that of a DSO that contains named elements and their associated properties. A GlobeDoc allows elements to be added and removed, as well as the contents and properties of existing elements to be modified. A GlobeDoc's functionality is implemented by a semantics subobject having a set of predefined interfaces as shown in Figure 4.1. Clients use methods from these interfaces to access and modify the elements contained in a GlobeDoc.
interface document {
void addElement(name, elementType, contents);
void deleteElement(name);
name getRoot();
name[] allElements();
}
interface content {
contents getContent(name);
void putContent(name, checkId, contents);
void putAllContent(checkId, contents[]);
}
interface property {
properties getProperties(name);
void setProperties(name, properties);
}
interface lock {
checkId checkOutElements(name[]);
void checkInElements(checkId);
name[] getCheckedElements(checkId);
}
The document interface contains methods that act on the document as a whole. It allows elements to be added and removed, as well as element names to be retrieved. An element is always referenced by its name, which is a character string. The content interface is used to retrieve and set an element's contents. The contents are contained in a byte array. Note, that the putContent and putAllContent methods require a checkId as a parameter. This identifier is related to the locking mechanism and will be described shortly. An element's properties can be set and retrieved through the property interface. Properties are represented as strings of (attribute,value) pairs.
Modifying an element is a three-step process. In the first step, a copy of an element's contents must be extracted with the getContent method. Next, the element can be modified using an appropriate tool, such as an HTML or image editor. When all modifications have been made, the element is returned to the GlobeDoc using the putContent method. To keep a GlobeDoc's state consistent we have included a locking mechanism. This mechanism ensures that an element is only modified by one client at a time. A client that wishes to modify an element must lock (check out) that element before modifying it. To enforce this, an element's contents can be replaced only when given a valid lock identifier. A lock identifier can be acquired only when locking an element. The lock interface provides methods that implement this mechanism. checkOutElements is called to lock an element. It returns a checkId, which is the lock identifier and can be supplied as a parameter when calling putContent. An element can be unlocked with the checkInElement method.
Internally an element is stored in a record containing fields for the element's name, properties and contents. The contents are always stored as a byte array. Multiple element records are stored in a table and are indexed by the element names. A separate table stores locking information such as checkIds and their associated element names. Note that the GlobeDoc interfaces are independent of a GlobeDoc's implementation. It is therefore possible to replcae the implementation of a GlobeDoc without affecting the applications that use it.
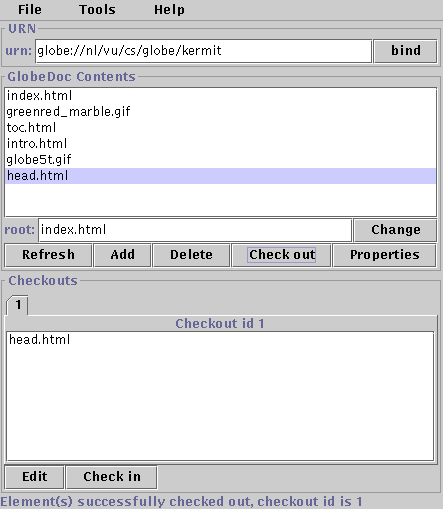
globe:/nl/vu/cs/globe/gdObject:/element.html, for example, refers to an element named /element.html in a GlobeDoc named /nl/vu/cs/globe/gdObject. A GlobeDoc URI with an empty element name implicitly refers to the root element. For integration in the current Web, GlobeDoc URIs can be embedded in URLs in the same way as regular Globe URIs, for example as http://globe.cs.vu.nl/nl/vu/cs/globe/gdObject:/element.html. Note that element names are never stored in the Globe name service. Thus, when resolving a GlobeDoc URI, the GlobeDoc and element names must be separated before attempting to resolve the object name.We have built a number of user level tools for creating and managing GlobeDoc objects. They range from a simple command line tool for creating GlobeDocs, to a GUI tool that allows full management of existing GlobeDocs. The latter is shown in Figure 4.2. Although these tools are specific for GlobeDoc, they can be generalized and used for practically any kind of Globe object.
The Web consists of more than just simple Web documents; there is a wide range of different resources such as interactive Web pages, dynamic Web services, streaming media, large files (such as films), etc. The GlobeDoc interface is adequate for simple documents and possibly simple dynamic documents, but it is inappropriate for other, more complex, resources. This is because different types of resources have specific needs and should be encapsulated in their own classes of Globe objects. For example, Globe objects encapsulating streaming media would require an interface that allows clients to sequentially read parts of the data, while interactive Web resources require an interface that allows clients to interact with the object. Each of the different resources will also most likely require different distribution strategies. For example, while for many GlobeDocs, state can be entirely stored in a single LRs memory, the state of an object encapsulating a large media resource might need to be partitioned and divided over the object's LRs.
Adding new Web resource objects to a Web architecture based on Globe is quite straightforward. Due to the modular structure of LRs, the semantics subobject is the only component that must be designed and implemented anew. Globe servers can host new kinds of Globe objects without affecting their current implementation. Naming, location, and implementation services are likewise unaffected. This is a large improvement over the current HTTP based architecture, where the introduction of new functionality often requires changes to the underlying framework. For example, the CC/PP exchange protocol [19] is an extension to the HTTP protocol that allows user capabilities and preferences to be exchanged. Because this protocol introduces new headers to HTTP, its implemention requires changes to all Web servers and clients desiring to use it. In our approach such extensive changes would not be necessary. The only changes that would have to be made would be to the semantics subobject of appropriate Globe objects. Such changes would automatically be distributed to new clients through the implementation repository during binding.
We have built a small GlobeDoc 'Web service' (publicly accessible from the Globe home page) that implements all the main components of a Globe Web system (translator, gateway, runtime system, Globe object). The service contains GlobeDocs that encapsulate the Web documents on the Globe Web site and is being used as a first test of the architecture. The general configuration is similar to that in Figure 2.4, however, instead of one global Globe server that contains all the GlobeDocs, each GlobeDoc object is started in its own Globe server. These Globe servers are quite simple and do not yet offer a remote interface for their management.
Our Web service contains a translator and gateway for access from regular Web browsers. As described in previous sections, the translator translates all URIs in the served pages to appropriate URLs and the gateway performs method calls on the LRs. We have also implemented a Globe aware version of Mozilla that recognizes Globe URIs and forwards the requests directly to the gateway (bypassing the translator). All Globe components, except for our adaptation of Mozilla, are implemented in Java.
To experiment with Globe's flexible approach to distribution strategies, we have implemented some simple replication strategies. The simplest one is client/server interaction. In this strategy there is one LR that acts as a server and contains all of the object state (i.e., all the elements). The rest of the LRs are stateless clients that forward all requests to and receive all replies from the server. We have also implemented active replication where all the LRs contain full replicas of the state. Read operations are served locally by a LR, while write operations are forwarded to and executed on all LRs. Another strategy that we have implemented is a simple master/slave variation. In this strategy all LRs have a replica of the state, but only one master LR is allowed to perform updates. When the master performs an update it sends a message to all the other LRs informing them of the update. Due to the simplicity of the current configuration we have not yet had a chance to test more complex strategies or combinations of replication and coherency strategies.
Much attention has been focused on improving the performance of the Web. The most common of such improvements being various caching architectures ranging from relatively simple browser and proxy caches to more complex hierarchical caches [7] and push caches [11]. Other attempts focus on replication or mirroring of content, including simple mirroring, clustering [3], and architectures such as those provided by Akamai [1] and Sandpiper [22]. All these approaches have in common that they are add-on mechanisms, that is, they do not attempt to modify HTTP - the fundamental nonscalable base of the Web. Thus, even though these solutions offer some performance gains, they are not flexible enough to adapt to the different replication needs of various Web resources. They provide only one-size-fits-all solutions.
Attempts at modifying the actual infrastructure are much less common. The W3C itself has been working on improving the current HTTP standard by adding extension mechanisms [17], and relaying caching information along with requests and replies [10]. Once again, we feel that these solutions are not flexible enough, and do not offer the possibility of tailoring solutions to specific Web resources. There is also work being done on a location-independent naming scheme for the Web based on URNs [24]. We are currently looking at how our name service could be applied to the URN work [6]. Another W3C project that considers completely replacing the Web infrastructure by a distributed object based infrastructure is HTTP-NG [18]. Though this is similar to our approach in Globe, HTTP-NG focuses on the actual communication model and does not offer the flexibility with regards to distribution strategy that Globe does. Another project that introduces an object-based Web infrastructure is the W3Objects system [12]. This system allows objects to have their own replication scheme, however, it strives for high visibility of caching mechanisms, while Globe aims at providing replication transparency.
With regards to distributed object models, related work includes CORBA [20], DCOM [9] and Java RMI [27]. The main difference with all these models to Globe is that they provide remote objects, rather than physically distributed objects. An approach based on remote objects makes it harder to adopt object-specific solutions. As such, we feel that Globe provides a much more flexible model for state distribution. A model that does provide physically distributed objects is that based on fragmented objects [15]. Although fragmented objects have been designed to encapsulate their own distribution policy, they have not been designed with worldwide scalability in mind.
In this paper we have presented Web resources encapsulated in Globe distributed shared objects as a replacement for the current World Wide Web architecture. By allowing scaling techniques to be applied on a per-object basis, scalable Globe objects can be created. In addition, our approach provides a flexible and extensible approach for implementing future objects. We described the Globe Web model and give details of the system components. We have also introduced GlobeDocs, which are encapsulated Web documents, and have described our current implementation of a Globe based Web architecture.
We are currently looking at the distribution needs of Web documents and are developing scalable distribution strategies for them. Besides Web documents we are also considering encapsulating other Web resources in Globe objects and determining their distribution needs. We are also currently working on creating a suitable container model for Globe objects [4]. Such a container will act as the 'glue' that holds all the various Web resources together (much like HTML does nowadays). Furthermore, we are investigating how security can be incorporated into the framework so that security policies can be attached to individual Globe objects in a similar way as done with distribution now. The current implementation will be used to perform experiments with GlobeDoc objects to get performance measurements and statistics on a local as well as global scale.